|
|
for simulation of 3D problems of continuous media dynamics |
Introduction | |
Numerical Algorithm | |
Parallel Implementation | |
Results of Test Problem Simulation | |
Comparison of Different Computer Systems | |
References |
Introduction.
The problem is extremely actual for modern aerospace applications
of detailed investigation of the oscillating regimes in transsonic
and supersonic viscous gas flows over various bodies. Under
certain freestream conditions such flows may be characterized by
regular self-induced pressure oscillations. Their frequency,
amplitude and harmonic properties depend upon the body geometry
and external flow conditions. It is possible that these pulsations
may have a destructive influence upon mechanical properties of the
different aircraft parts especially in the resonant case. From
mathematical point of view such 3D problems are quite difficult
for numerical simulation and are a subject of interest for many
scientific laboratories. The program package for the simulation
of such problems is developped in our Institute. It is designed
for using on high performance multiprocessor computer systems.
Making choice of numerical method we have to take into account the fact that to predict a detailed structure of unsteady viscous compressible gas flow we need to use high performance parallel computer systems. The opinion is widely spread that for viscous gas flow simulation we have to use only implicit schemes because of their good stability properties. When modeling the stationary problems we usually don't interested in the details of stabilization process. So it is naturally to use some implicit scheme which permits the program to run with large time step. In the case of essentially unsteady flow, especially for oscillating regimes, we have to receive detailed information about high frequency pulsations of gas dynamic parameters. This fact limits the time step acceptable for the difference scheme by the accuracy requirements. For many interesting problems these limitations neutralize the advantages of implicit schemes. So for such problems the explicit difference schemes seem to be preferable because of their simplicity for program realization, especially for parallel implementation. For this reason one of the explicit versions of original algorithms named kinetically consistent finite difference (KCFD) schemes (see [1]) was selected for numerical simulation of essentially unsteady viscous gas flows.
Numerical Algorithm.
The kinetic schemes differ from the other algorithms primarily in
that the basis for their foundation is the discrete model for
one-particle distribution function. The averaging of this model by
the molecular velocities with the collision vector components
results in the production of the difference schemes for gas
dynamic parameters. The successful experience in solving various
gas dynamic problems by means of such schemes [2,
3,4] showed that they describe
viscous heat conducting flows as good as other (non kinetic) difference
schemes for Navier-Stokes equations where the last are applicable.
In addition, these schemes permit to calculate oscillating regimes in
super- and transsonic gas flows, which are very difficult for
modeling by means of other algorithms. It's also must be mentioned
that the numerical algorithms for KCFD schemes are very convenient
for the adaptation on the massively parallel computer systems with
distributed memory architecture. This fact gives the opportunity
to use very fine meshes, which permit to study the fine structure
of flow.
The explicit variant of these schemes (KCFD with correction [5]) with soft stability condition: time step equal to O(h) - was used as the numerical background for our parallel software. These schemes are homogeneous schemes i.e. one type of algorithm describe as viscous as inviscous parts of the flow. The geometrical parallelism principle have been implemented for constructing their parallel realization. This means that each processor provides calculation in its own subdomain. The explicit form of schemes allows to minimize the exchange of information between processors. Having equal number of grid nodes in each subdomain the homogeneity of algorithm automatically provides processors load balancing. The real efficiency of parallelization for explicit schemes close to 100% may be achieved for practically any number of processors.
It may also be mentioned that the choice of numerical method is not critical for the program package presented. Any conservative scheme may be rewritten in a conservation-law form. So in order to change one explicit scheme to another in this package one have to do nothing but rewrite the subroutine which calculates the flows between grid cells. Not only difference scheme but also the governing equations may be replaced in a similar manner if they allow a conservation-law form.
Parallel Implementation.
The developing of applied software intended for numerical
simulation of 3D flows is a very painstaking job, especially while
creating distributed applied software for MIMD computers. In order
to simplify our work we decided to follow some quite obvious but
important principles:
| - all complicated but not very time-consuming operations must be processed by separate sequential programs; |
| - every combined operation ought to be subdivided by several independent simple operations; |
| - essentially parallel program must be as simple as possible and have extremely clear logical structure. |
The basic ideas accepted determined the structure of whole software bundle. Total data processing procedure consist of three separate stages:
| - covering full mesh region by subdomains, every of which will be processed on one processor; |
| - converting the content of files with task geometry data, boundary conditions and some auxiliary information into data of several formats, every of which specially suited for specific internal needs; final preparations for distributed calculations; |
| - fulfilling parallel computations. |
C and Fortran languages were used to develop software. MPI libraries were taken for realization of message passing at the distributed stage. Two first stages are carried out by sequential programs. First of them divides complete computational volume into necessary number of 3D rectangular subvolumes. This fragmentation must provide processors load balancing and minimal messages interchange among processors in accordance with geometry parallelism principle. The result of this stage is the text file describing 3D subvolumes in terms of grid nodes numbers. User can edit this file manually if needed.
Description of task geometry, boundary conditions and grid information are kept in another text file. Special simple language is used for this description. Particular compiler translates content of this file to intermediate arrays in some format convenient for further transformations. These arrays contain vertices point coordinates, information about body surface and so on. They are later used for results visualization (Geometry description language is not specifically gas dynamic and can be used for description of tasks of another physical nature.) Compiler implements syntax checking during data input. It is necessary in order to keep out of different kinds of mistakes especially in the case of complex body shape. When catching any syntax mistake compiler issues appropriate diagnostic message and bug location.
The data obtained are the input for modules, which transform and organize them for parallel computations by several steps. Final data structure tuned for minimal interchange between CPU and RAM. Last action of the second stage is to allocate needed data to binary files every of which contains data portion, needed for one processor.
The last stage is the start of distributed computational program. The main criteria of this program is efficiency. To satisfy this requirement it's logical structure is done as clear, compact and simple as possible. In addition this approach essentially simplifies the debugging process.
Results of Test Problem Simulation.
The problem of viscous compressible gas flow along the plane
surface with rectangular cavity in it was taken as a test problem.
Such a flow is characterized by a complex unsteady flowfields. The
numerical experiments were made for time-constant freestream
parameters which were taken in accordance with the experimental
data [6],
| - inflow Mach number 1.35; |
| - Reynolds number 33000; |
| - Prandtl number 0.72; |
| - share layer thickness near separation d/h = 0.041; |
| - relative cavity length l/h = 2.1; |
| - relative cavity width w/h = 2.0. |
As experiments [6] as previous calculations [7, 8] show that the intensive pressure pulsations in the cavity took place for such inflow parameters and cavity geometry. The computational region is presented on Figure 1. The inflow is parallel to the XY-plane and makes angle y with the X direction. The geometrical parameters of cavity and computational region are determined by coordinates of points A, B, C, D, E, F on Figure 1. Their values are
| A=(2.1,0.0,0.0), | B=(2.1,1.0,0.0), | C=(2.1,0.0,-1.0), |
| D=(-2.0,0.00.0), | E=(5.5,0.0,0.0), | F=(0.0,3.0,0.0). |
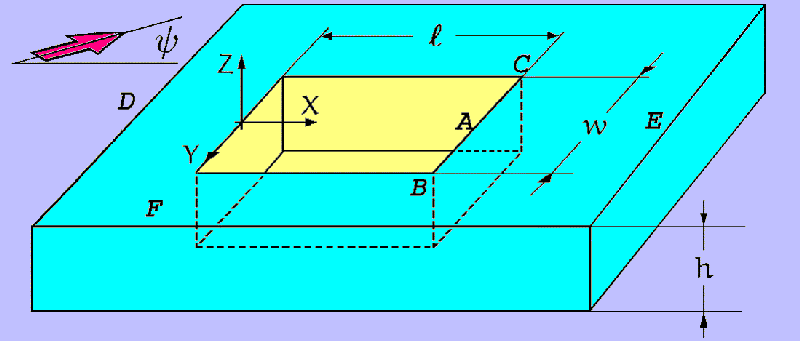
Figure 1. The scheme of computational region.
The beginning distribution corresponds to share layer over the cavity and immobile gas with the braking parameters inside it. The calculations were accomplished on rectangular grid with the total number of cells over 1200000. Detailed information of 3D gas flow around the open cavity was obtained for different angles of incidence y.
For y=0 the 3D gas flow structure in the middle part of the cavity was approximately the same as for the 2D problem. (see Figures 2a, 2b)
The most interesting 3D motion was observed in the vicinity of output cavity corner and edges of the long cavity sides for nonzero incidence angle. Lengthwise gas movement was combined with traverse one in these regions resulting in the gas vortices and swirls appearance. Periodical processes of gas input and output through the side cavity edges occurred. The intensive traverse oscillations occur in the cavity for such inflow in addition to previous ones observed in the case of zero angle. Nonzero incident angle leads to appearance of traverse vortical motion over whole cavity (oscillation of longwise swirls) and some vortices in the XY-plane inside the cavity. These results are illustrated on Figures 3a, 3b, 3c. Properties of pressure oscillations in critical cavity points were studied. The spectrum analysis of these oscillations was carried out. This analysis showed the presence of the intensive high frequency discrete components. They had the most amplitudes close to cavity rear bulkhead and were absent in the cavity central zone. Areas of the most probable wreckage on the cavity surface were revealed.Comparison of Different Computer Systems.
The program package was tested on MIMD computers with MPP architecture (MCS-1000, Parsytec CC), with SMP architecture (HP V2250) and Beowulf cluster.
64-processor MCS-1000 computer system is equipped with 533MHz Alpha 21164 EV5 chips. Host computer functions under Digital Unix or Linux operating systems. Slave processors function under VxWorks operating systems. This computer has rather slow processor interchange communication channels.
MPP computer Parsytec CC is equipped with twelve 133MHz PowerPC-604 chips. Fast interprocessor exchange communication channels has bandwidth up to 40 MBytes/Sec. All nodes function under IBM AIX 4.1.4 operating system.
SMP computer HP V2250 is equipped with 16 superscalar RISC 240MHz HP PA-8200 chips and 16GBytes RAM. It functions under HPUX 11.0 operating system. This computer demonstrated the most high reliability.
Beowulf cluster is combined by 16 dual-processor IBM PC nodes. Every computer is equipped with two 550MHz Pentium-III chips with 512 MBytes RAM. Each node function under Red Hut Linux 2.2.5. All nodes connected by 100MBit/Sec Ethernet local area network. Beowulf cluster had insufficient reliability at testing time, however it had the best performance/price ratio.
The simulation of above test problem using these computers yields us following results (equal number of processors used):
| 1) | HP V2250 | - 2.40 relative performance units; |
| 2) | Beowulf cluster | - 1.90 relative performance units; |
| 3) | MCS-1000 | - 1.70 relative performance units; |
| 4) | Parsytec CC | - 0.44 relative performance units; |
Worth be mentioned that the equipment + system software couples were tested. It means that modification of important components of system software (i.e. high level language compiler or MPI libraries) may substantially (with ratio 1.5-2.0) change final results. Authors do not have certain information if every tested MIMD system were provided with the most appropriate system software.